Integrated Storage
OpenBao supports a number of storage options for the durable storage of OpenBao's information. This Integrated Storage backend does not rely on any third party systems, implements High Availability semantics and provides backup/restore workflows.
The option stores OpenBao's data on the server's filesystem and uses a consensus protocol to replicate data to each server in the cluster. More information on the internals of Integrated Storage can be found in the Integrated Storage internals documentation. Additionally, the Configuration docs can help in configuring OpenBao to use Integrated Storage.
The sections below go into various details on how to operate OpenBao with Integrated Storage.
Server-to-Server communication
Once nodes are joined to one another they begin to communicate using mTLS over
OpenBao's cluster port. The cluster port defaults to 8201. The TLS information
is exchanged at join time and is rotated on a cadence.
A requirement for Integrated Storage is that the
cluster_addr configuration option
is set. This allows OpenBao to assign an address to the node ID at join time.
Cluster membership
This section will outline how to bootstrap and manage a cluster of OpenBao nodes running Integrated Storage.
Integrated Storage is bootstrapped during the initialization process and results in a cluster of size 1. Depending on the desired deployment size, nodes can be joined to the active OpenBao node.
Joining nodes
Joining is the process of taking an uninitialized OpenBao node and making it a member of an existing cluster. In order to authenticate the new node to the cluster it must use the same seal mechanism. If using a Auto Unseal the node must be configured to use the same KMS provider and Key as the cluster it's attempting to join. If using a Shamir seal the unseal keys must be provided to the new node before the join process can complete. Once a node has successfully joined, data from the active node can begin to replicate to it. Once a node has been joined it cannot be re-joined to a different cluster.
You can either join the node automatically via the config file or manually through the
API (both methods described below). When joining a node, the API address of the leader node must be used. We
recommend setting the api_addr configuration
option on all nodes to make joining simpler.
retry_join configuration
This method enables setting one, or more, target leader nodes in the config file. When an uninitialized OpenBao server starts up it will attempt to join each potential leader that is defined, retrying until successful. When one of the specified leaders becomes active this node will successfully join. When using Shamir seal, the joined nodes will still need to be unsealed manually. When using Auto Unseal the node will be able to join and unseal automatically.
An example retry_join
config can be seen below:
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
leader_api_addr = "https://node1.openbao.local:8200"
}
retry_join {
leader_api_addr = "https://node2.openbao.local:8200"
}
}
Note, in each retry_join
stanza, you may provide a single
leader_api_addr or
auto_join value. When a cloud
auto_join configuration value is
provided, OpenBao will use go-discover
to automatically attempt to discover and resolve potential Raft leader
addresses.
See the go-discover
README for
details on the format of the auto_join value.
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
auto_join = "provider=aws region=eu-west-1 tag_key=openbao tag_value=... access_key_id=... secret_access_key=..."
}
}
By default, OpenBao will attempt to reach discovered peers using HTTPS and port 8200. Operators may override these through the
auto_join_scheme and
auto_join_port fields
respectively.
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
auto_join = "provider=aws region=eu-west-1 tag_key=openbao tag_value=... access_key_id=... secret_access_key=..."
auto_join_scheme = "http"
auto_join_port = 8201
}
}
Join from the CLI
Alternatively you can use the join CLI
command or the API to join a node. The
active node's API address will need to be specified:
$ bao operator raft join https://node1.openbao.local:8200
Non-Voting nodes
Nodes that are joined to a cluster can be specified as non-voters. A non-voting node has all of OpenBao's data replicated to it, but does not contribute to the quorum count. This can be used to add read scalability to a cluster in cases where a high volume of reads to servers are needed.
$ bao operator raft join -non-voter https://node1.openbao.local:8200
Removing peers
Removing a peer node is a necessary step when you no longer want the node in the cluster. This could happen if the node is rotated for a new one, the hostname permanently changes and can no longer be accessed, you're attempting to shrink the size of the cluster, or for many other reasons. Removing the peer will ensure the cluster stays at the desired size, and that quorum is maintained.
To remove the peer you can issue a
remove-peer command and provide the
node ID you wish to remove:
$ bao operator raft remove-peer node1
Peer removed successfully!
Listing peers
To see the current peer set for the cluster you can issue a
list-peers command. All the voting
nodes that are listed here contribute to the quorum and a majority must be alive
for Integrated Storage to continue to operate.
$ bao operator raft list-peers
Node Address State Voter
---- ------- ----- -----
node1 node1.openbao.local:8201 follower true
node2 node2.openbao.local:8201 follower true
node3 node3.openbao.local:8201 leader true
Integrated Storage and TLS
We've glossed over some details in the above sections on bootstrapping clusters. The instructions are sufficient for most cases, but some users have run into problems when using auto-join and TLS in conjunction with things like auto-scaling. The issue is that go-discover on most platforms returns IPs (not hostnames), and because the IPs aren't knowable in advance, the TLS certificates used to secure the OpenBao API port don't contain these IPs in their IP SANs.
OpenBao networking recap
Before we explore solutions to this problem, let's recapitulate how OpenBao nodes speak to one another.
OpenBao exposes two TCP ports: the API port and the cluster port.
The API port is where clients send their OpenBao HTTP requests.
For a single-node OpenBao cluster you don't worry about a cluster port as it won't be used.
When you have multiple nodes, you also need a cluster port. This is used by OpenBao nodes to issue RPCs to one another, e.g. to forward requests from a standby node to the active node, or when Raft is in use, to handle leader election and replication of stored data.
The cluster port is secured using a TLS certificate that the OpenBao active node generates internally. It's clear how this can work when not using integrated storage: every node has at least read access to storage, so once the active node has persisted the certificate, the standby nodes can fetch it, and all agree on how cluster traffic should be encrypted.
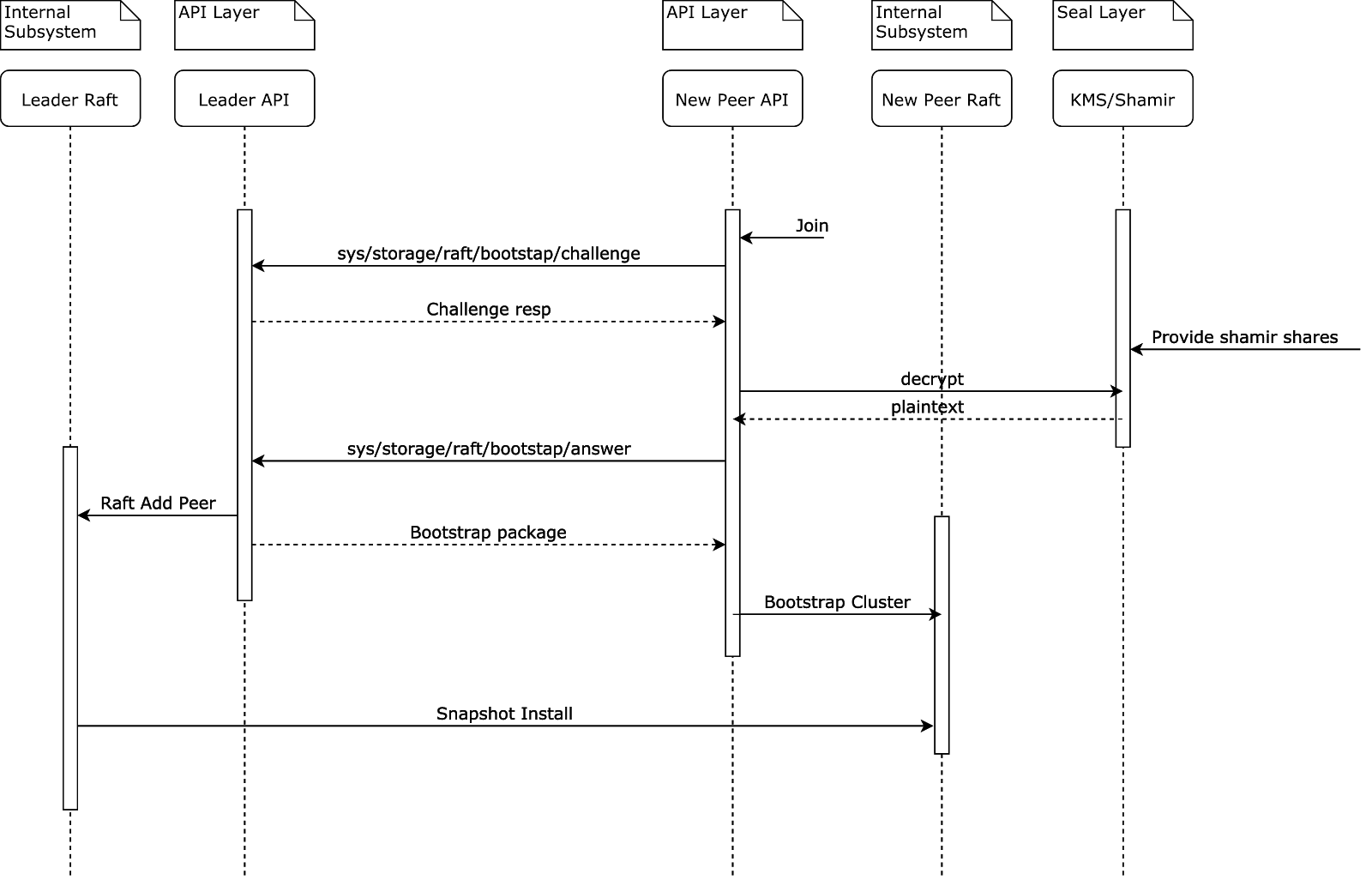
It's less clear how this works with Integrated Storage, as there is a chicken and egg problem. Nodes don't have a shared view of storage until the raft cluster has been formed, but we're trying to form the raft cluster! To solve this problem, an OpenBao node must speak to another OpenBao node using the API port instead of the cluster port. This is currently the only situation in which OpenBao does this.
node2wants to join the cluster, so issues challenge API request to existing membernode1node1replies to challenge request with (1) an encrypted random UUID and (2) seal confignode2must decrypt UUID using seal; if using auto-unseal can do it directly, if using Shamir must wait for user to provide enough unseal keys to perform decryptionnode2sends decrypted UUID back tonode1using answer APInode1seesnode2can be trusted (since it has seal access) and replies with a bootstrap package which includes the cluster TLS certificate and private keynode2gets sent a raft snapshot over the cluster port
After this procedure the new node will never again send traffic to the API port. All subsequent inter-node communication will use the cluster port.
Assisted raft join techniques
The simplest option is to do it by hand: issue raft join commands specifying the explicit names
or IPs of the nodes to join to. In this section we look at other TLS-compatible
options that lend themselves more to automation.
Autojoin with TLS servername
The simplest option might be to specify a
leader_tls_servername
in the retry_join
stanza which matches a DNS
SAN in the certificate.
Note that names in a certificate's DNS SAN don't actually have to be registered
in a DNS server. Your nodes may have no names found in DNS, while still
using certificate(s) that contain this shared servername in their DNS SANs.
Autojoin but constrain CIDR, list all possible IPs in certificate
If all the OpenBao node IPs are assigned from a small subnet, e.g. a /28, it
becomes practical to put all the IPs that exist in that subnet into the IP SANs
of the TLS certificate the nodes will share.
The drawback here is that the cluster may someday outgrow the CIDR and changing it may be a pain. For similar reasons this solution may be impractical when using non-voting nodes and dynamically scaling clusters.
Load balancer instead of autojoin
Most OpenBao instances are going to have a load balancer (LB) between clients and
the OpenBao nodes. In that case, the LB knows how to route traffic to working
OpenBao nodes, and there's no need for auto-join: we can just use
retry_join with the LB
address as the target.
One potential issue here: some users want a public facing LB for clients to connect to OpenBao, but aren't comfortable with OpenBao internal traffic egressing from the internal network it normally runs on.
Outage recovery
Quorum maintained
This section outlines the steps to take when a single server or multiple servers are in a failed state but quorum is still maintained. This means the remaining alive servers are still operational, can elect a leader, and are able to process write requests.
If the failed server is recoverable, the best option is to bring it back online and have it reconnect to the cluster with the same host address. This will return the cluster to a fully healthy state.
If this is impractical, you need to remove the failed server. Usually, you can
issue a remove-peer command to
remove the failed server if it's still a member of the cluster.
If the remove-peer command isn't
possible or you'd rather manually re-write the cluster membership a
raft/peers.json file can be written to the
configured data directory.
Quorum lost
In the event that multiple servers are lost, causing a loss of quorum and a complete outage, partial recovery is still possible.
If the failed servers are recoverable, the best option is to bring them back online and have them reconnect to the cluster using the same host addresses. This will return the cluster to a fully healthy state.
If the failed servers are not recoverable, partial recovery is possible using data on the remaining servers in the cluster. There may be data loss in this situation because multiple servers were lost, so information about what's committed could be incomplete. The recovery process implicitly commits all outstanding Raft log entries, so it's also possible to commit data that was uncommitted before the failure.
See the section below on manual recovery using
peers.json for details of the recovery
procedure. You include only the remaining servers in the
peers.json recovery file. The cluster
should be able to elect a leader once the remaining servers are all restarted
with an identical peers.json
configuration.
Any servers you introduce later can be fresh with totally clean data directories and joined using OpenBao's join command.
In extreme cases, it should be possible to recover with just a single remaining
server by starting that single server with itself as the only peer in the
peers.json recovery file.
Manual recovery using peers.json
Using raft/peers.json for recovery can cause uncommitted Raft log entries to be
implicitly committed, so this should only be used after an outage where no other
option is available to recover a lost server. Make sure you don't have any
automated processes that will put the peers file in place on a periodic basis.
To begin, stop all remaining servers.
The next step is to go to the configured data
path of each OpenBao server. Inside that
directory, there will be a raft/ sub-directory. We need to create a
raft/peers.json file. The file should be formatted as a JSON array containing
the node ID, address:port, and suffrage information of each OpenBao server you
wish to be in the cluster:
[
{
"id": "node1",
"address": "node1.openbao.local:8201",
"non_voter": false
},
{
"id": "node2",
"address": "node2.openbao.local:8201",
"non_voter": false
},
{
"id": "node3",
"address": "node3.openbao.local:8201",
"non_voter": false
}
]
id(string: <required>)- Specifies the node ID of the server. This can be found in the config file, or inside thenode-idfile in the server's data directory if it was auto-generated.address(string: <required>)- Specifies the host and port of the server. The port is the server's cluster port.
Create entries for all servers. You must confirm that servers you do not include here have indeed failed and will not later rejoin the cluster. Ensure that this file is the same across all remaining server nodes.
At this point, you can restart all the remaining servers. The cluster should be in an operable state again. One of the nodes should claim leadership and become active.
Other recovery methods
For other, non-quorum related recovery OpenBao's recovery mode can be used.